






SIGMETRICS Tutorial: MapReduce - Google Research.
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner. A MapReduce job usually splits the input data-set into independent chunks which are.
Google.org issued an open call to organizations around the world to submit their ideas for how they could use AI to help address societal challenges. Meet the 20 organizations we selected to support. Introduction to Federated Learning.
Data science is the extension of research findings and drawing conclusions from data(1). BigTable is built on a few of Google technologies(2). MapReduce is a programming model and an associated.
Programmers find the system easy to use: hundreds of MapReduce programs have been implemented and upwards of one thousand MapReduce jobs are executed on Google's clusters every day. View the full text of this paper in HTML and PDF. Until December 2005, you will need your USENIX membership identification in order to access the full papers.
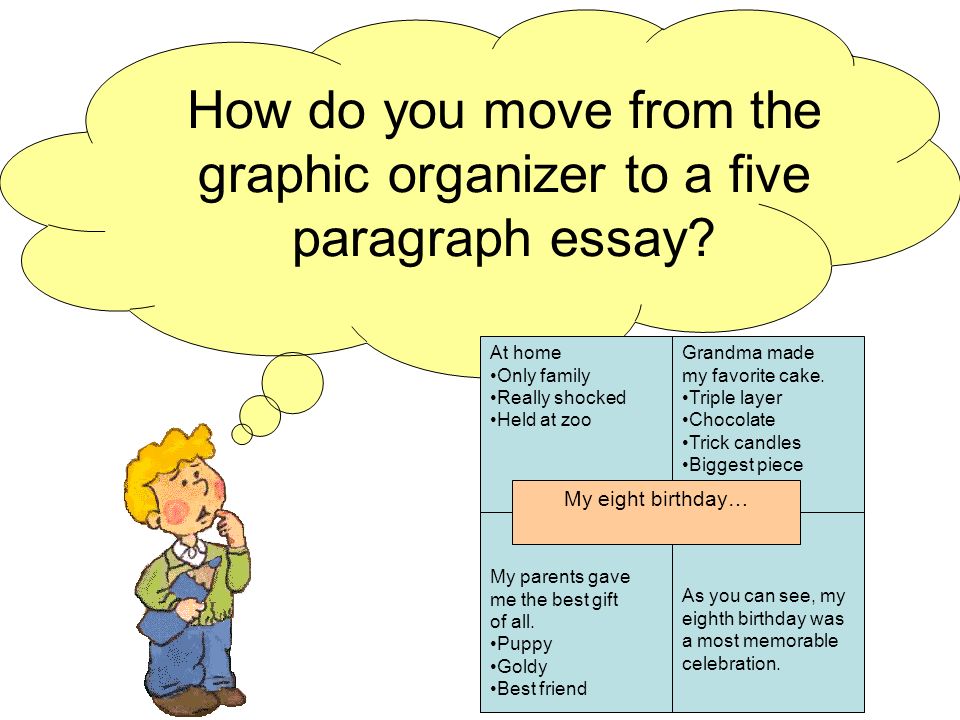
Steps of a MapReduce Job 1.Hadoop divides the data into input splits, and creates one map task for each split. 2.Each mapper reads each record (each line) of its input split, and outputs a key-value pair.
MapReduce advantages over parallel databases include storage-system independence and fine-grain fault tolerance for large jobs.
We now provide background on MapReduce frameworks and demonstrate our synthesis approach with examples. 2.1 Data-parallel programming frameworks Since the introduction of Google’s MapReduce system in Dean and Ghemawat’s seminal paper (25), a number of powerful systems that implement and extend the MapReduce paradigm have been.


